O “Software Bill of Materials” (SBOM – Lista de Materiais de Software), fazendo um paralelo, é o equivalente, em um software, a lista de ingredientes nas embalagens de alimentos. Pessoas alérgicas a algum componente dos ingredientes do produto podem ter essa informação nessa lista impressa na embalagem.
Esses ingredientes podem conter um componente de terceiro, com a caseína que compõe o leite, por exemplo, e assim o consumidor alérgico à caseína pode evitá-lo por saber que o leite é um dos ingredientes. Mas as SBOMs vão além de uma simples lista de ingredientes.
Em termos de software, um componente de terceiros é uma dependência e cada dependência pode ter subdependências. Esses componentes, dependências e subdependências podem incluir projetos de software de código aberto, código proprietário, APIs, estruturas de linguagem de programação e bibliotecas de software.
O conceito SBOM surgiu pela primeira vez no final da década de 1990 como uma ferramenta local, limitada a equipes internas de desenvolvimento.
Em 2007, foi ampliado para permitir rastreamento e conformidade com licenciamento de software de terceiros.
Em 2018, grupos de trabalho públicos/privados organizados fora da NTIA, coordenados pelo Dr. Alan Friedman, começaram a trabalhar seriamente para expandir e desenvolver SBOMs em uma ferramenta útil de segurança cibernética.
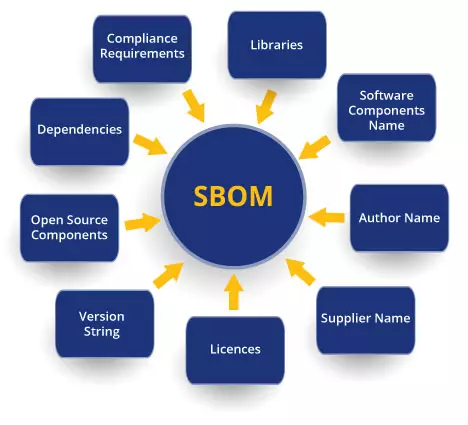
Já Julho de 2021, a Administração Nacional de Telecomunicações e Informações (NTIA) emitiu orientações definitivas em um relatório detalhando os elementos mínimos para um SBOM.Alguns dos pontos dessa orientação são:
- Qual versão foi usada?
- De onde foi originado o componente?
- Quais os relacionamentos deste componente?
- Qual o nome do autor e do fornecedor?
A lista completa de elementos está disponível na Administração Nacional de Telecomunicações e Comunicações do Departamento de Comércio (NTIA).
Source: https://www.erp-information.com/wp-content/uploads/2022/06/sbom-format.png
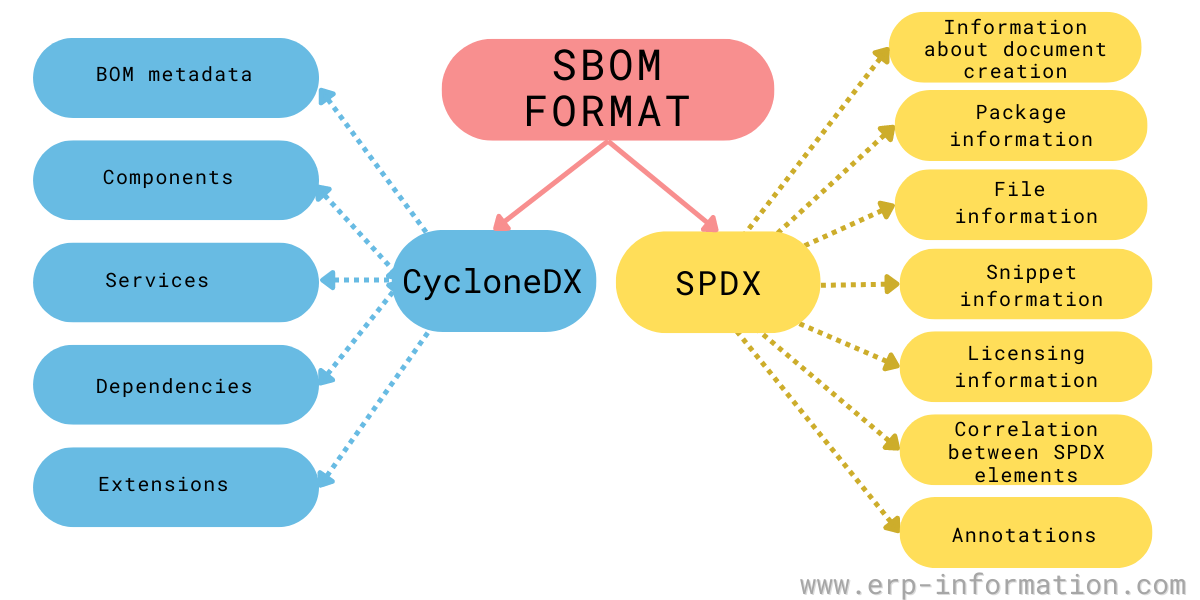
Isso tudo pode ser muito complicado para uma empresa catalogar. Para ajudar essa organização, existem dois padrões mais conhecidos: SPDX e CycloneDx
SPDX é um padrão aberto para comunicação de informações SBOM, incluindo proveniência, licença, segurança e outras informações relacionadas e é um padrão internacional reconhecido pela ISO/IEC 5962:2021
CycloneDX , uma ferramenta SBOM originalmente criada por Steve Springett e agora uma iniciativa OWASP (Open Web Application Security Project).
Quando as vulnerabilidades de software são descobertas, elas geralmente são encontradas em componentes que são dependências de outros aplicativos de software. Saber se uma organização está em risco devido a um componente de terceiros é um desafio comumente chamado de Risco da cadeia de suprimentos (Supply Chain). Os ataques à integridade da cadeia de suprimentos tem se tornado mais comuns, causando prejuízos de bilhões de dólares como foi o caso dos ataques as empresas Solarwinds e Codecov.
Uma proposta para a melhor proteção da cadeia de suprimentos é a adoção da Supply chain Levels for Software Artifacts (SLSA ou SALSA) que é um framework que garante segurança a cadeia de suprimentos (assunto para um outro post mais detalhado).
Muitas organizações enfrentam o desafio de saber se estão em risco devido a uma vulnerabilidade de software. Quando a vulnerabilidade “Heartbleed” foi divulgada em 2014 (CVE-2014-0160), todos os aplicativos e serviços que dependiam do OpenSSL como dependência precisavam ser atualizados.
O mesmo tipo de risco também foi exposto pela vulnerabilidade de software de código aberto Log4J (CVE-2021-44228) que foi divulgada em dezembro de 2021. Mesmo depois que um componente ou biblioteca de origem é corrigido pelo projeto original, cabe ao fornecedor mantenedor do componente, e de cada usuário final corrigir a vulnerabilidade atualizando o componente.
Em um cenário onde os softwares de algumas empresas podem conter até 90% do código bibliotecas opensource em sua composição (20% sendo o framework, 70% bibliotecas importadas para problemas simples), é de extrema importância saber quais componentes estão sendo utilizados, além das suas subdependências. Essa prática é utilizada para ajudar a entender e mitigar vulnerabilidades conhecidas no código, economizando tempo e custos.
Os SBOMs também ajudam os departamentos jurídicos e de conformidade a identificar o histórico de licenças e os casos de uso permitidos para um código de terceiros, o que reduz qualquer uso indevido em potencial. Além disso, os SBOMs ajudam as equipes de segurança e forense a identificar o impacto no software após a descoberta de vulnerabilidades e exposições comuns (CVEs) recém-identificadas, que melhoram a capacidade das organizações de responder e corrigir.
Uma lista de aplicativos que podem gerar uma lista SBOM:
Microsoft SBOM Tool
Trivy
Syft
Opensbom Generator
CycloneDX
KubeClarity
FossID – Snyk
Mend
Ao som de: David Bowie – Moonage Daydream