A cadeia de suprimentos, também conhecida como Supply Chain Management (SCM), é o conjunto de atividades que envolvem a produção, armazenamento e transporte de produtos ou serviços. Isso inclui a compra de matérias-primas, controle de estoque e o transporte do produto até o cliente final, definição dada no artigo da Voitto.
Certo, mas qual seria a cadeia de suprimentos de uma aplicação? Como definir esse conceito para a construção de um software? Fácil! Todo o processo de construção de uma aplicação faz parte dessa cadeia, afinal teremos uma entrega a um cliente final da mesma forma.
Para fazer uma analogia, vamos supor uma empresa XPTO que fabrique “Camisas Sociais de Luxo”. Essa empresa XPTO terá que selecionar as melhores matérias primas, como tecidos de alta qualidade. O maquinário que irá fazer o corte e costura dessas camisas devem ser específico para essa finalidade, assim como os funcionários devem ser treinados para manusear essa matéria prima e esses equipamentos. Outro ponto que pode ser observado é o transporte dessas camisas ao lojista que irá vendê-las. As camisas não podem sair da fábrica de uma forma e chegar de outra forma. Além disso, o próprio lojista deve ser qualificado para oferecer a melhor experiência para o cliente final. Todo esse processo é monitorado, verificado e medido para garantir a qualidade ofertada ao cliente final.
Para um software, devemos ter os mesmos cuidados, porém trazendo para a realidade da construção de uma aplicação. Desde a escolha da linguagem de programação, fazer a modelagem de ameaças, utilizar as melhores práticas de desenvolvimento seguro, scans de vulnerabilidades automatizados, proteção das aplicações de CI/CD, assim como a proteção da rede e dos ambientes onde serão feitos os deploys. Lembrando que isso é apenas um exemplo, o nível das escolhas pode variar bastante como até mesmo a escolha dos fabricantes dos chips, qual provedor de cloud, entre outros detalhes.
O NIST (National Institute for Standards and Technology) define o ataque à cadeia de suprimentos como “Ataques que permitem ao atacante implantar ou usar vulnerabilidades inseridas antes da instalação para infiltrar dados ou manipular hardware, software, sistemas operacionais, periféricos ou serviços de tecnologia da informação em qualquer ponto durante o ciclo de vida do desenvolvimento do software.” Na relatório “2022 AppSec Trend Report” da MicroFocus, a segurança da cadeia de suprimentos é o primeiro tópico a ser abordado. Os ataques ao log4j e à Solarwinds também são mencionados como exemplos nesse relatório.
A ENISA (European Union Agency for Cybersecurity) publicou um relatório onde ela classifica que o ataque à cadeia de suprimentos tem uma combinação de dois alvos: O primeiro é fornecedor que é usado para atacar o alvo para obter acesso aos seus ativos e o segundo é o cliente final, ou outro fornecedor, que utiliza o software ou hardware desse fornecedor.
Além desses dos alvos, a ENISA também definiu quatro características principais em um ataque à cadeia de suprimentos:
- Técnicas de ataque usadas para comprometer o fornecedor;
- Ativos do fornecedor visados no ataque;
- Técnicas de ataque usadas para comprometer o cliente;
- Ativos do cliente visados no ataque;
1 – “Técnicas de ataque usadas para comprometer o fornecedor” se preocupam como o ataque ocorreu e não como foi utilizado para fazer o ataque. Alguns exemplos são: Engenharia Social, Ataque de Força Bruta, OSINT, Exploração de Vulnerabilidade de um Software;
2 – “Ativos do fornecedor visados no ataque” referem-se a qual foi o alvo do ataque ao fornecedor. Os exemplos são: Bibliotecas importadas ao código, Código proprietário, Processos ou Pessoas;
3 – “Técnicas de ataque usadas para comprometer o cliente” faz referência como o cliente foi atacado: “Trusted Relationship” [T1199], Phishing [T1566], “Drive-by Compromise” [T1189] Ataque ou Modificação Física;
4 – “Ativos do cliente visados no ataque” é o principal e final alvo do ataque, também sendo a razão do ataque. Geralmente, mais de um cliente é afetado por esses ataques. Os exemplos são: Dados profissionais ou pessoais, Ataques Financeiros, Infraestrutura de Rede (DDOS, SPAM…).
Depois de fazer o levantamento dos dados, basta cruzá-los para compreender como o ataque foi realizado com sucesso.
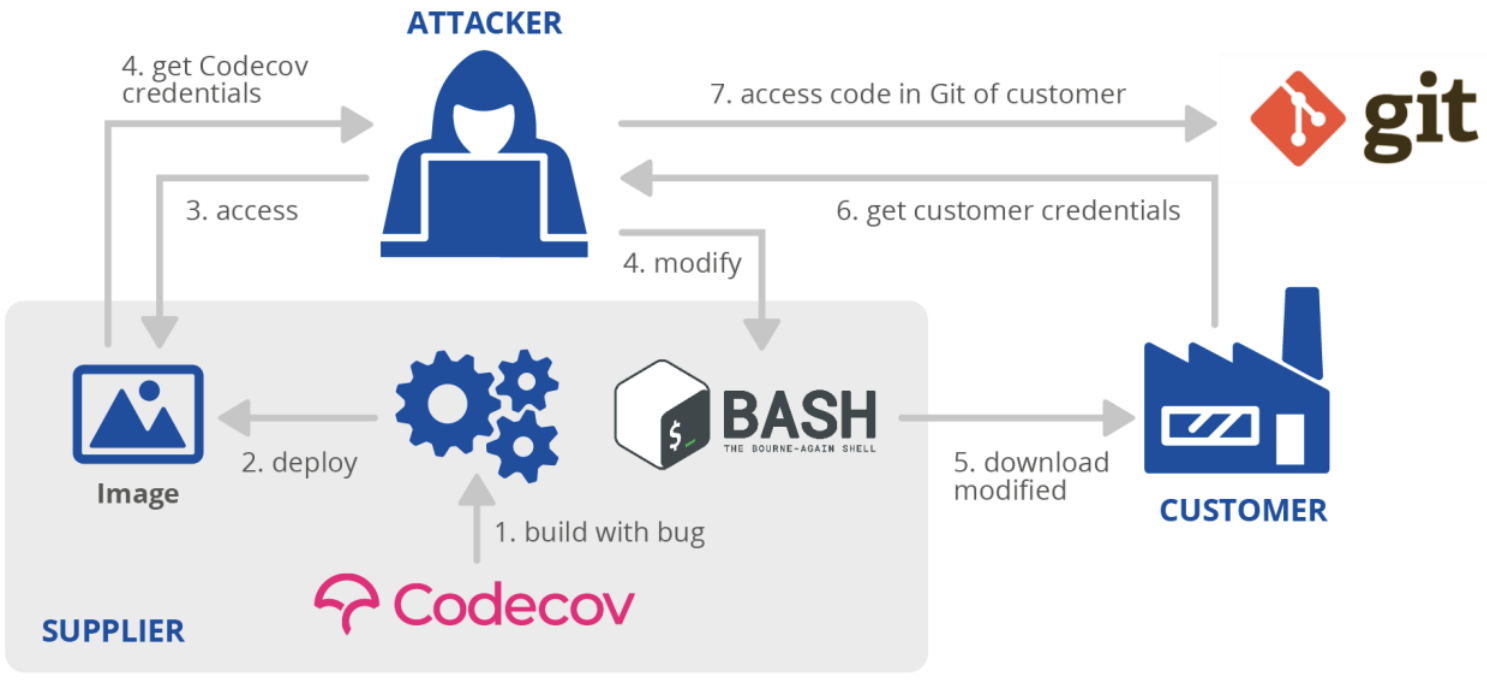
Como exemplo, vamos verificar como foi o ataque ao CodeCov:

- O processo de criação do container Codecov tinha um bug que estava presente nos containers implantados online;
- Os invasores acessaram o container e obtiveram as credenciais do Codecov;
- Eles então modificaram o script bash do Codecov;
- E esse novo script que foi modificado, foi atualizado nos clientes;
- O script bash malicioso exfiltrava as credenciais do cliente para o invasor;
- O invasor utilizava as credenciais para acessar os dados dos clientes.
Referenciando as quatro características, podemos utilizar os dados da seguinte forma:
| FORNECEDOR | CLIENTE |
| Técnicas de ataque usadas para comprometer o fornecedor | Ativos do fornecedor visados no ataque | Técnicas de ataque usadas para comprometer o cliente | Ativos do cliente visados no ataque |
| Explorar Vulnerabilidade de Configuração; | Código | “Trusted Relationship” [T1199]; | Software |
Pode ser complexo garantir a segurança da cadeia de suprimentos, porém é muito importante ter em mente que deve esse tipo de ataque está ocorrendo com mais frequência. Adotar medidas de segurança, é um processo de amadurecimento e nesse caso pode ser implementado por equipes em paralelo.
Referências:
https://www.enisa.europa.eu/publications/threat-landscape-for-supply-chain-attacks
https://debricked.com/blog/software-supply-chain-attacks-part-one/
https://www.cyberark.com/resources/blog/breaking-down-the-codecov-attack-finding-a-malicious-needle-in-a-code-haystack
https://community.microfocus.com/cyberres/b/sws-22/posts/appsec-trends-securing-the-software-supply-chain
Ao som de: Opeth – In My Time Of Need